
Vertex Deployment
Overview: Google Vertex AI Pipelines
In this brief tutorial, we will explore how to build an AutoML tabular classification workflow using the google_cloud_pipeline_components SDK in Vertex AI Pipelines. The steps covered include setting up a pipeline to train a model using the UCI ‘Dry Beans’ dataset and deploying the trained model on a Vertex AI Endpoint.
Learn more about Vertex AI Pipelines and AutoML components. The code is based on guides provided on GoogleCloudPlatform repository and an AutoML Classification example
Objective
This tutorial demonstrates how to:
- Create a Vertex AI Dataset using a Kubeflow Pipeline.
- Train a tabular classification model using AutoML.
- Deploy the trained model to a Vertex AI Endpoint.
- Compile and execute the pipeline using Vertex AI Pipelines.
We will be using the following Google Cloud services:
- Vertex AI Pipelines
- Google Cloud Pipeline Components
- Vertex AutoML
- Vertex AI Model
- Vertex AI Endpoint
Dataset
We will use the UCI ‘Dry Beans’ dataset for this tutorial, which is available in the following paper:
Koklu, M. and Ozkan, I.A., (2020), “Multiclass Classification of Dry Beans Using Computer Vision and Machine Learning Techniques.” DOI.
Costs
This tutorial uses billable components of Google Cloud, including:
- Vertex AI
- Cloud Storage
For pricing details, visit the Vertex AI pricing page and the Cloud Storage pricing page.
Getting Started
Install Required Packages
Install the necessary Python packages and restart the runtime to use updated packages.
! pip3 install --upgrade --quiet google-cloud-aiplatform \
google-cloud-storage \
kfp \
google-cloud-pipeline-components
import sys
if "google.colab" in sys.modules:
import IPython
app = IPython.Application.instance()
app.kernel.do_shutdown(True)
Authenticate and Set up
The following code will authenticate and set up the necessary environment packages / variables for a pipeline. Please note to add your own relevant PROJECT_ID , LOCATION, and SERVICE_ACCOUNT.
# authenticate notebook environment
import sys
if "google.colab" in sys.modules:
from google.colab import auth
auth.authenticate_user()
# set google cloud project information, fill in project_id & location
PROJECT_ID = "" # @param {type:"string"}
LOCATION = "us-central1" # @param {type:"string"}
# create cloud storage bucket
BUCKET_URI = f"gs://your-bucket-name-{PROJECT_ID}-unique" # @param {type:"string"}
! gsutil mb -l {LOCATION} -p {PROJECT_ID} {BUCKET_URI}
# set service account
SERVICE_ACCOUNT = "" # @param {type:"string"}
# set service account access
! gsutil iam ch serviceAccount:{SERVICE_ACCOUNT}:roles/storage.objectCreator
# import libraries
from typing import NamedTuple
import google.cloud.aiplatform as aiplatform
import kfp
from google.cloud import bigquery
from kfp import compiler, dsl
from kfp.dsl import (Artifact, ClassificationMetrics, Input, Metrics, Output,
component)
# vertex ai constants
# set path for storing the pipeline artifacts
PIPELINE_NAME = "automl-tabular-beans-training"
PIPELINE_ROOT = "{}/pipeline_root/beans".format(BUCKET_URI)
# initialize vertex ai asdk for python
aiplatform.init(project=PROJECT_ID, location=LOCATION, staging_bucket=BUCKET_URI)
Pipeline components
In this section, you’ll create a custom pipeline component, while using other pre-built components from Vertex AI services.
The custom component is based on a Python function. Using Python makes it easier to quickly build and test your code. The @component decorator turns your Python function into a task that can be used in the pipeline.
When the function is evaluated, a YAML file (tabular_eval_component.yaml) is generated. This file defines the component, can be version-controlled, and reused in future pipelines. It also specifies the base image (Python 3.7 by default) and installs the google-cloud-aiplatform package.
The custom component retrieves evaluation metrics from an AutoML tabular model, visualizes the ROC curve and confusion matrix, and checks if the model is accurate enough for deployment.
@component(
base_image="gcr.io/deeplearning-platform-release/tf2-cpu.2-6:latest",
packages_to_install=["google-cloud-aiplatform"],
)
def classification_model_eval_metrics(
project: str,
location: str,
thresholds_dict_str: str,
model: Input[Artifact],
metrics: Output[Metrics],
metricsc: Output[ClassificationMetrics],
) -> NamedTuple("Outputs", [("dep_decision", str)]): # Return parameter.
import json
import logging
from google.cloud import aiplatform
aiplatform.init(project=project)
# Fetch model eval info
def get_eval_info(model):
response = model.list_model_evaluations()
metrics_list = []
metrics_string_list = []
for evaluation in response:
evaluation = evaluation.to_dict()
print("model_evaluation")
print(" name:", evaluation["name"])
print(" metrics_schema_uri:", evaluation["metricsSchemaUri"])
metrics = evaluation["metrics"]
for metric in metrics.keys():
logging.info("metric: %s, value: %s", metric, metrics[metric])
metrics_str = json.dumps(metrics)
metrics_list.append(metrics)
metrics_string_list.append(metrics_str)
return (
evaluation["name"],
metrics_list,
metrics_string_list,
)
# Use the given metrics threshold(s) to determine whether the model is
# accurate enough to deploy.
def classification_thresholds_check(metrics_dict, thresholds_dict):
for k, v in thresholds_dict.items():
logging.info("k {}, v {}".format(k, v))
if k in ["auRoc", "auPrc"]: # higher is better
if metrics_dict[k] < v: # if under threshold, don't deploy
logging.info("{} < {}; returning False".format(metrics_dict[k], v))
return False
logging.info("threshold checks passed.")
return True
def log_metrics(metrics_list, metricsc):
test_confusion_matrix = metrics_list[0]["confusionMatrix"]
logging.info("rows: %s", test_confusion_matrix["rows"])
# log the ROC curve
fpr = []
tpr = []
thresholds = []
for item in metrics_list[0]["confidenceMetrics"]:
fpr.append(item.get("falsePositiveRate", 0.0))
tpr.append(item.get("recall", 0.0))
thresholds.append(item.get("confidenceThreshold", 0.0))
print(f"fpr: {fpr}")
print(f"tpr: {tpr}")
print(f"thresholds: {thresholds}")
metricsc.log_roc_curve(fpr, tpr, thresholds)
# log the confusion matrix
annotations = []
for item in test_confusion_matrix["annotationSpecs"]:
annotations.append(item["displayName"])
logging.info("confusion matrix annotations: %s", annotations)
metricsc.log_confusion_matrix(
annotations,
test_confusion_matrix["rows"],
)
# log textual metrics info as well
for metric in metrics_list[0].keys():
if metric != "confidenceMetrics":
val_string = json.dumps(metrics_list[0][metric])
metrics.log_metric(metric, val_string)
logging.getLogger().setLevel(logging.INFO)
# extract the model resource name from the input Model Artifact
model_resource_path = model.metadata["resourceName"]
logging.info("model path: %s", model_resource_path)
# Get the trained model resource
model = aiplatform.Model(model_resource_path)
# Get model evaluation metrics from the the trained model
eval_name, metrics_list, metrics_str_list = get_eval_info(model)
logging.info("got evaluation name: %s", eval_name)
logging.info("got metrics list: %s", metrics_list)
log_metrics(metrics_list, metricsc)
thresholds_dict = json.loads(thresholds_dict_str)
deploy = classification_thresholds_check(metrics_list[0], thresholds_dict)
if deploy:
dep_decision = "true"
else:
dep_decision = "false"
logging.info("deployment decision is %s", dep_decision)
return (dep_decision,)
compiler.Compiler().compile(
classification_model_eval_metrics, "tabular_eval_component.yaml"
)
Define pipeline
This code defines a Kubeflow pipeline using the Vertex AI Pipelines SDK for automating a tabular classification workflow in Google Cloud. An explanation of the steps is provided below the code.
@kfp.dsl.pipeline(name=PIPELINE_NAME, pipeline_root=PIPELINE_ROOT)
def pipeline(
bq_source: str,
DATASET_DISPLAY_NAME: str,
TRAINING_DISPLAY_NAME: str,
MODEL_DISPLAY_NAME: str,
ENDPOINT_DISPLAY_NAME: str,
MACHINE_TYPE: str,
project: str,
gcp_region: str,
thresholds_dict_str: str,
):
from google_cloud_pipeline_components.v1.automl.training_job import \
AutoMLTabularTrainingJobRunOp
from google_cloud_pipeline_components.v1.dataset.create_tabular_dataset.component import \
tabular_dataset_create as TabularDatasetCreateOp
from google_cloud_pipeline_components.v1.endpoint.create_endpoint.component import \
endpoint_create as EndpointCreateOp
from google_cloud_pipeline_components.v1.endpoint.deploy_model.component import \
model_deploy as ModelDeployOp
dataset_create_op = TabularDatasetCreateOp(
project=project,
location=gcp_region,
display_name=DATASET_DISPLAY_NAME,
bq_source=bq_source,
)
training_op = AutoMLTabularTrainingJobRunOp(
project=project,
location=gcp_region,
display_name=TRAINING_DISPLAY_NAME,
optimization_prediction_type="classification",
optimization_objective="minimize-log-loss",
budget_milli_node_hours=1000,
model_display_name=MODEL_DISPLAY_NAME,
column_specs={
"Area": "numeric",
"Perimeter": "numeric",
"MajorAxisLength": "numeric",
"MinorAxisLength": "numeric",
"AspectRation": "numeric",
"Eccentricity": "numeric",
"ConvexArea": "numeric",
"EquivDiameter": "numeric",
"Extent": "numeric",
"Solidity": "numeric",
"roundness": "numeric",
"Compactness": "numeric",
"ShapeFactor1": "numeric",
"ShapeFactor2": "numeric",
"ShapeFactor3": "numeric",
"ShapeFactor4": "numeric",
"Class": "categorical",
},
dataset=dataset_create_op.outputs["dataset"],
target_column="Class",
)
model_eval_task = classification_model_eval_metrics(
project=project,
location=gcp_region,
thresholds_dict_str=thresholds_dict_str,
model=training_op.outputs["model"],
)
with dsl.If(
model_eval_task.outputs["dep_decision"] == "true",
name="deploy_decision",
):
endpoint_op = EndpointCreateOp(
project=project,
location=gcp_region,
display_name=ENDPOINT_DISPLAY_NAME,
)
ModelDeployOp(
model=training_op.outputs["model"],
endpoint=endpoint_op.outputs["endpoint"],
dedicated_resources_min_replica_count=1,
dedicated_resources_max_replica_count=1,
dedicated_resources_machine_type=MACHINE_TYPE,
)
1. Pipeline with Kubeflow
- @kfp.dsl.pipeline: This decorator defines the function as a Kubeflow pipeline.
- Input Parameters: The pipeline accepts various input parameters like the BigQuery source (bq_source), display names for the dataset, training job, model, and endpoint, as well as information like project ID, GCP region, machine type for deployment, and model evaluation thresholds.
These parameters are critical for customizing the pipeline’s behavior and configuring it based on specific project requirements.
2. Import Google Cloud Components
The next section of the code imports various Google Cloud components from the Vertex AI SDK that are needed to create datasets, train the model, and manage endpoints.
AutoMLTabularTrainingJobRunOp: Runs a Vertex AI AutoML training job on tabular data.
TabularDatasetCreateOp: Creates a tabular dataset in Vertex AI using data from BigQuery.
EndpointCreateOp: Creates an endpoint in Vertex AI to deploy models.
ModelDeployOp: Deploys a trained model to a specified endpoint.
3. Dataset Creation
The pipeline imports a tabular dataset from BigQuery.
dataset_create_op: This operation creates a dataset using the specified BigQuery source. The resulting dataset will be used as input for the AutoML training process.Parameters: The operation requires the project ID, GCP region, display name for the dataset, and the BigQuery source table.
4. AutoML Training Job
Once the dataset is ready, the pipeline initiates an AutoML Tabular Training Job. This job trains a machine learning model on the tabular data, aiming to optimize the prediction of a classification target.
AutoMLTabularTrainingJobRunOp: This operation runs an AutoML training job for classification. The goal is to minimize log loss, which is a common objective for classification tasks.budget_milli_node_hours: Specifies the training budget, which limits how much time AutoML can spend training the model.column_specs: Defines the data types of the columns in the dataset, with most being numeric except the target column (Class), which is categorical.
5. Model Evaluation
After the model has been trained, the pipeline evaluates it using a custom model evaluation component.
model_eval_task: This operation evaluates the trained model. The evaluation compares the model’s performance against predefined thresholds, which are passed in as thresholds_dict_str.Outputs: This operation generates evaluation metrics and a decision on whether the model meets the deployment criteria.
6. Conditional Model Deployment
Based on the evaluation results, the pipeline can conditionally deploy the model. If the model meets the evaluation criteria, it will be deployed to an endpoint in Vertex AI.
dsl.If: This is a conditional statement that checks if the model evaluation meets the criteria for deployment. Ifdep_decisionis true, the model is deployed. The pipeline creates a new endpoint in Vertex AI where the model will be deployed.EndpointCreateOp: This operation creates an endpoint where the trained model will be hosted and served.ModelDeployOp: This operation deploys the model to the endpoint with specific configurations for machine resources, including the machine type and the number of replicas.
Compile pipeline
compiler.Compiler().compile(
pipeline_func=pipeline,
package_path="tabular_classification_pipeline.yaml",
)
Run pipeline
Pass the input parameters required for the pipeline and run it. The defined pipeline takes the following parameters:
bq_source: BigQuery source for the tabular dataset.
DATASET_DISPLAY_NAME: Display name for the Vertex AI managed dataset.
TRAINIG_DISPLAY_NAME: Display name for the AutoML training job.
MODEL_DISPLAY_NAME: Display name for the Vertex AI model generated as a result of the training job.
ENDPOINT_DISPLAY_NAME: Display name for the Vertex AI endpoint where the model is deployed.
MACHINE_TYPE: Machine type for the serving container.
project: Id of the project where the pipeline is run.
gcp_region: Region for setting the pipeline location.
thresholds_dict_str: Dictionary of thresholds based on which the model deployment is conditioned.
pipeline_root: To override the pipeline root path specified in the pipeline job’s definition, specify a path that your pipeline job can access, such as a Cloud Storage bucket URI.
PIPELINE_DISPLAY_NAME = "pipeline_beans-unique" # @param {type:"string"}
DATASET_DISPLAY_NAME = "dataset_beans-unique" # @param {type:"string"}
MODEL_DISPLAY_NAME = "model_beans-unique" # @param {type:"string"}
TRAINING_DISPLAY_NAME = "automl_training_beans-unique" # @param {type:"string"}
ENDPOINT_DISPLAY_NAME = "endpoint_beans-unique" # @param {type:"string"}
# Set machine type
MACHINE_TYPE = "n1-standard-4"
# Validate region of the given source (BigQuery) against region of the pipeline
bq_source = "aju-dev-demos.beans.beans1"
client = bigquery.Client()
bq_region = client.get_table(bq_source).location.lower()
try:
assert bq_region in LOCATION
print(f"Region validated: {LOCATION}")
except AssertionError:
print(
"Please make sure the region of BigQuery (source) and that of the pipeline are the same."
)
# Configure the pipeline
job = aiplatform.PipelineJob(
display_name=PIPELINE_DISPLAY_NAME,
template_path="tabular_classification_pipeline.yaml",
pipeline_root=PIPELINE_ROOT,
parameter_values={
"project": PROJECT_ID,
"gcp_region": LOCATION,
"bq_source": f"bq://{bq_source}",
"thresholds_dict_str": '{"auRoc": 0.95}',
"DATASET_DISPLAY_NAME": DATASET_DISPLAY_NAME,
"TRAINING_DISPLAY_NAME": TRAINING_DISPLAY_NAME,
"MODEL_DISPLAY_NAME": MODEL_DISPLAY_NAME,
"ENDPOINT_DISPLAY_NAME": ENDPOINT_DISPLAY_NAME,
"MACHINE_TYPE": MACHINE_TYPE,
},
enable_caching=True,
)
# Run the job
job.run()
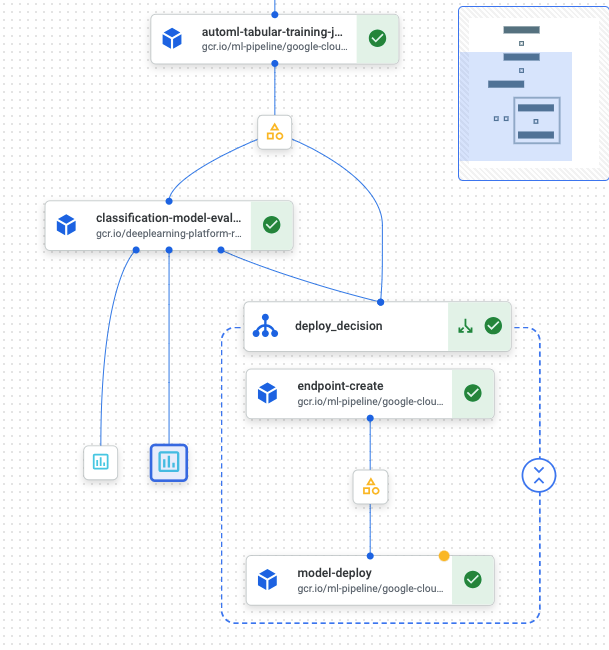
A successful run will show you a pipeline diagram below. In our example, the custom pipeline component outputs a step that renders the ROC curve and confusion matrix for the model.
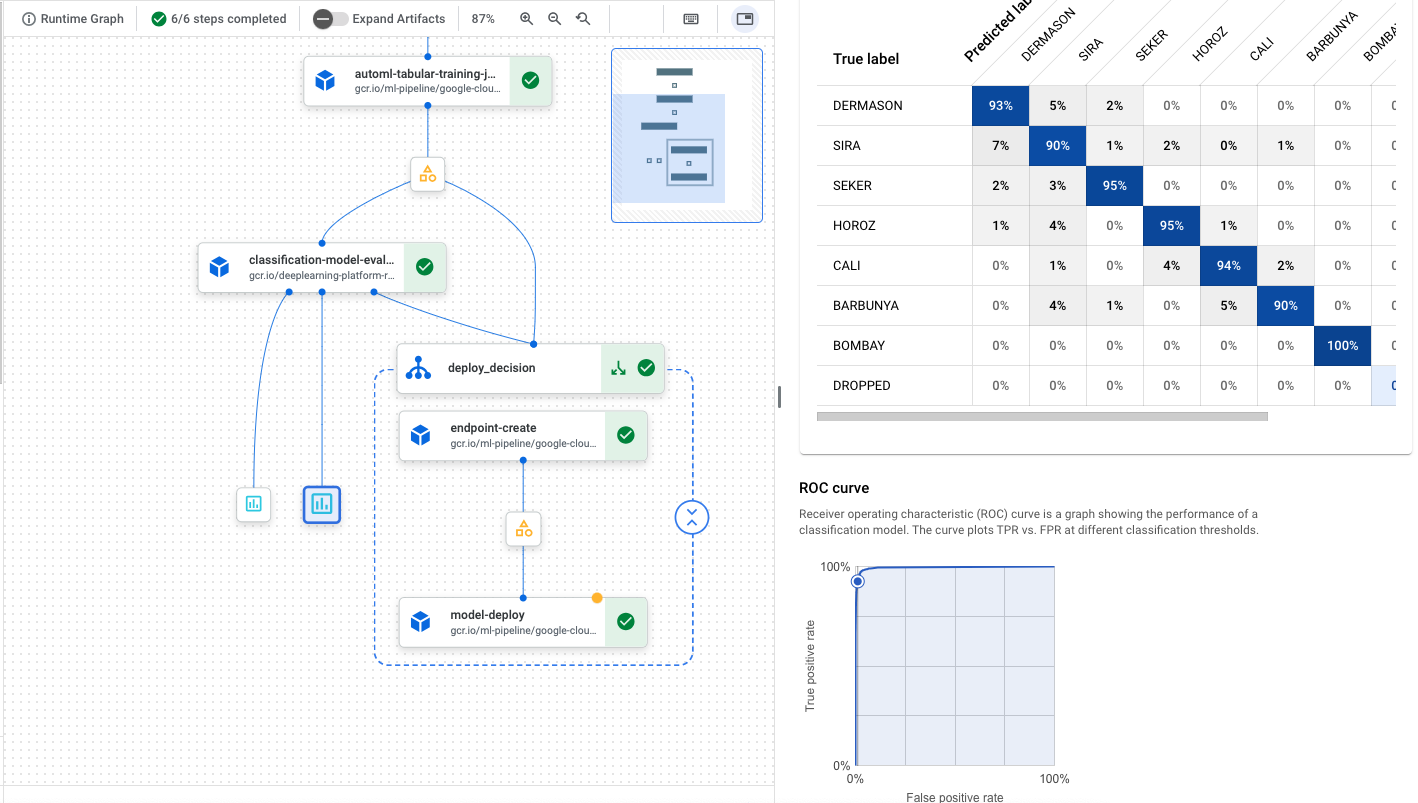
We can go to our model in the Model Registry and examine the metrics.

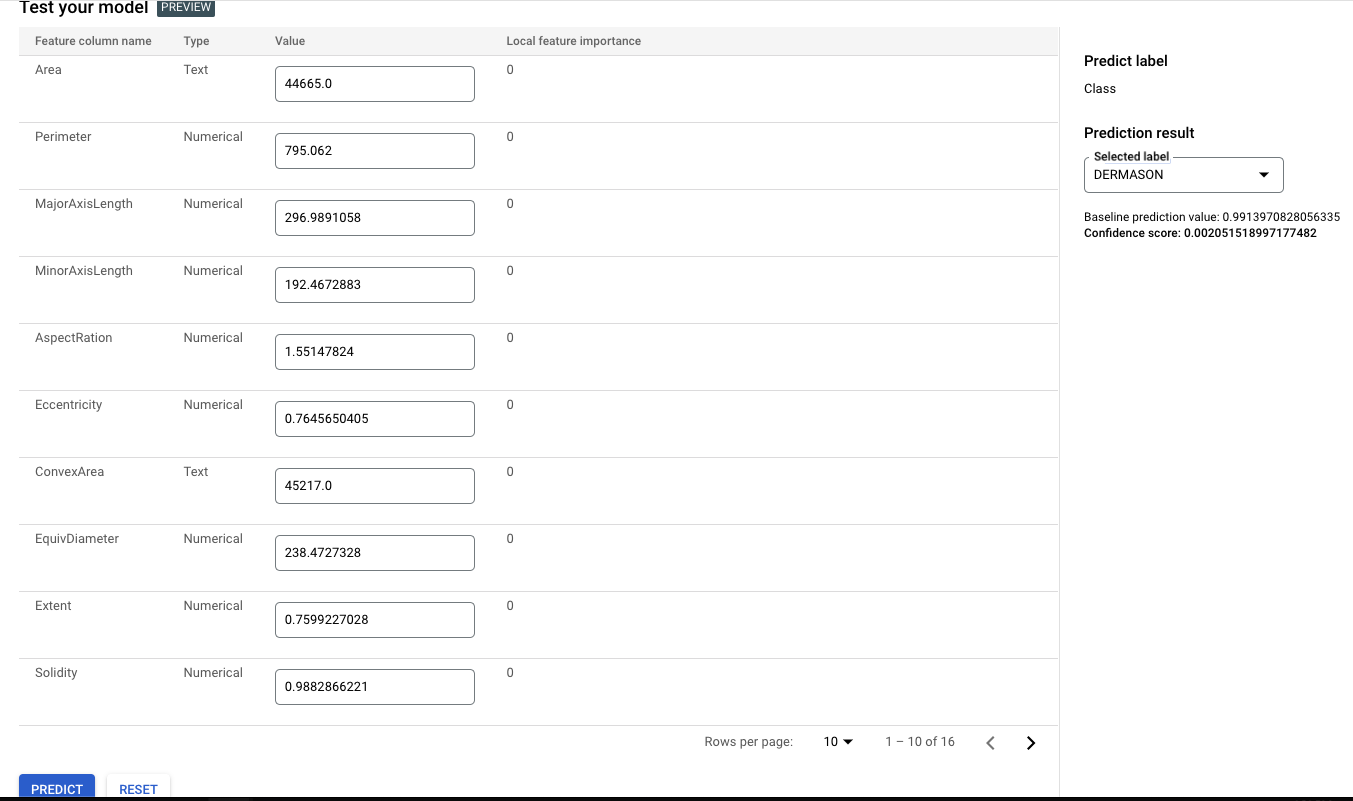
We can even input manual predictions to see what our predicted class will be!
Conclusion
This pipeline automates the entire machine learning lifecycle, from creating a dataset in BigQuery to training a model using Vertex AI AutoML, evaluating the model, and deploying it to an endpoint for production use. By leveraging Google Cloud’s Vertex AI components, this pipeline reduces the manual overhead in building and deploying machine learning models, providing a scalable and efficient workflow.